Como fizemos
A pesquisa desenvolvida seguiu o método de engenharia, ou seja, identificado o problema, buscou-se propor uma solução para o mesmo através de um produto. Além disso, ela se tratou de uma pesquisa aplicada, isto é, cuja produção de conhecimento foi dirigida à solução da questão escolhida.
No início do projeto, foram discutidas as possíveis ideias para o seu desenvolvimento, que envolveram temas como educação, bem estar digital, fake news e acessibilidade. Dois temas finais foram considerados: um aplicativo para o ensino de libras usando reconhecimento de imagem e um aplicativo para detectar deepfakes de áudio. A ideia escolhida foi a última, pela relevância e interesse pelo assunto.
Em seguida, realizou-se a pesquisa teórica do projeto, buscando-se fontes que indicassem a sua importância, como casos em que deepfakes trouxeram malefícios à sociedade, economia e política. Também começou-se a estudar metodologias para detectar deepfakes, com fundamentação baseada, quase inteiramente, no artigo Uncovering the Real Voice: How to Detect and Verify Audio Deepfakes, de Tan Jian Hong.
Considerando os dados presentes no artigo, decidiu-se que a metodologia empregada seria o uso de deep learning e, especialmente, visão computacional, para a detecção das deepfakes, pelas numerosas pesquisas que utilizaram a abordagem e atingiram resultados promissores.
Assim, seria necessário criar um modelo classificatório que, alimentado com dados sobre áudios reais e sintéticos, fosse capaz de classificá-los de acordo com sua respectiva categoria. Dessa forma, foi realizado o estudo sobre inteligência artificial, geração e identificação de deepfakes e o curso Intro to Deep Learning with TensorFlow, da plataforma Codecademy foi cursado, onde foram aprendidos conceitos e práticas essenciais para a estruturação, treinamento e validação de redes neurais.
Ademais, foi tomada a iniciativa de codificar um website em Next.js e uma API em Flask para permitir o uso, por usuários leigos, do modelo a ser desenvolvido no projeto, expandindo o acesso ao mesmo.
Para atingir os objetivos da pesquisa, seria necessário um dataset de áudios reais e sintéticos, que seria usado para o treinamento do modelo a ser desenvolvido. Assim, foi feita uma pesquisa de datasets já existentes elegíveis para esse fim, como o “ASVspoof 2019” (YAMAGISHI et al., 2019), contendo deepfakes criadas a partir de falas em inglês. Contudo, percebeu-se que não havia dataset específico para a língua portuguesa. Isso foi confirmado pelos artigos A Review of Modern Audio Deepfake Detection Methods: Challenges and Future Directions, de Almutairi e Elgibreen, e Audio deepfakes: A survey, de Khanjani, Watson e Janeja, o que levou à decisão de criar um Dataset inovador em português, permitindo a detecção de deepfakes na língua falada em território brasileiro.
À vista disso, a pesquisa consistiu, inicialmente, em encontrar um grande conjunto de áudios dos quais as vozes poderiam ser clonadas através de ferramentas de Text-to-Speech (TTS) ou Voice Conversion (VC), visando a produção de deepfakes.
Um desses bancos encontrado foi o Corpus do Centro de Estudos em Telecomunicações da PUC-Rio (CETUC) (OLIVEIRA, 2012), disponibilizado através do “Fala Brasil”, um grupo de pesquisa em processamento de fala em português brasileiro da Universidade Federal do Pará. O dataset é composto por áudios de cerca de 5 segundos com 1.000 sentenças, gravados por 101 locutores dos sexos masculino e feminino, totalizando aproximadamente 143 horas de áudio. Essas gravações, no formato wav, são acompanhadas de suas transcrições no formato txt.
Outro conjunto de dados encontrado foi o “Mozilla Common Voice” (ARDILA et al., 2019), que possui milhares de áudios agrupados juntamente com seus conteúdos em arquivos no formato csv. Seu lado negativo, porém, é a não diversidade de vozes, apesar da quantidade de horas em áudio disponibilizadas, que é muito elevada.
Com ambos os conjuntos de dados (áudios e transcrições) em mãos, iniciou-se a etapa de síntese de deepfakes. A primeira fase dessa etapa foi analisar as redes neurais existentes para esse fim. Entre os distintos modelos encontrados, destacam-se: Tacotron 2 (SHEN et al., 2017), Hifi-GAN (KONG; KIM, J; BAE, 2020), GlowTTS (KIM et al., 2020), WaveNet (VAN DEN OORD et al., 2016), entre outros.
Contudo, a maioria deles apresentou problemas de instalação de pacotes ou exigiu componentes gráficos avançados e tempo de execução muito acima do disponível. Além disso, eles não haviam sido treinados para a língua portuguesa, tornando-os impraticáveis para nossos objetivos.
Todavia, foi descoberto um modelo Text-To-Speech chamado “XTTS” (CASANOVA et al., 2024) que se destacou por ter sido treinado previamente em diferentes línguas, incluindo o português, e entregou resultados aceitáveis, além de ser open-source, isto é, com os códigos públicos. A arquitetura do modelo pode ser observada na Figura 2. Por falta de opções e recursos, ele foi utilizado para a produção do nosso Dataset, apesar de entendermos que, ao utilizar um só modelo, o conjunto de dados ficou limitado.
Figura 2: Arquitetura do modelo XTTS
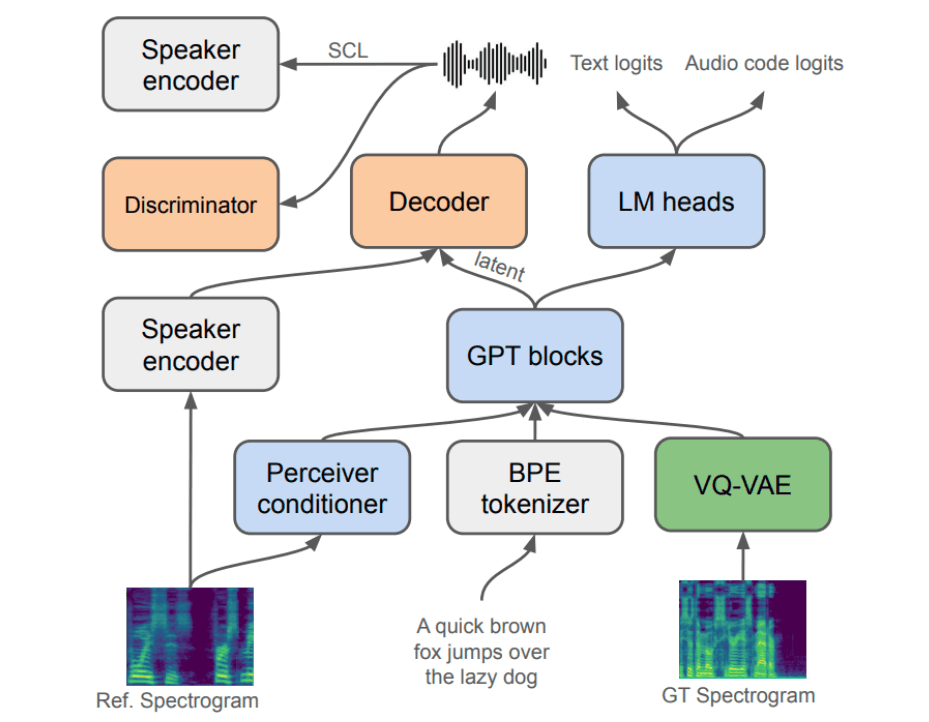
Fonte: XTTS: a Massively Multilingual Zero-Shot Text-to-Speech Model
Encontrado o modelo, foi decidido alimentá-lo com dados do Corpus do CETUC, pois ele contém gravações curtas, de até 10 segundos, somadas às suas transcrições, exatamente o exigido pela rede neural.
Assim, foi escrito um programa na linguagem de programação Python que, dada uma pasta contendo áudios e transcrições de uma das vozes, fornece esses dados para a rede, que então, através dos padrões de fala e das transcrições dos áudios, gera as deepfakes. O código foi feito baseado na documentação da biblioteca “Coqui-TTS” (GÖLGE et al., 2022), uma solução eficiente que possui funções prontas para geração de deepfakes através de modelos Text-To-Speech, permitindo a alimentação dos mesmos com vozes e textos customizados em um tempo de execução aceitável.
Em seguida, foi iniciada a produção do nosso Dataset, gerando, para cada voz do Corpus disponibilizado pelo grupo “Fala Brasil”, uma deepfake com o mesmo conteúdo contido nos arquivos texto do Corpus, isto é, das falas originais.
Após a produção dos áudios sintéticos, ocorreu a geração de espectrogramas do tipo constant-Q transform (CQT) (SCHÖRKHUBER; KLAPURI; 2010) das deepfakes e dos áudios do Corpus do CETUC, em escala cinza. Optou-se por essa abordagem pois, como já discutido, ela é mais eficaz para essa forma de detecção. Para a obtenção desses dados, foram empregadas bibliotecas na linguagem Python, tais como Librosa e Matplotlib, que permitem a manipulação desse tipo de conteúdo, com métodos para geração de espectrogramas CQT, redimensionamento das imagens e visualização das mesmas.
A formulação matemática envolvida na geração dos espectrogramas pode ser observada na Figura 3, que descreve a transformação CQT de um sinal discreto no domínio do tempo x(n). Já exemplos de imagens geradas podem ser vistos na Figura 4, onde, à direita, observa-se um espectrograma de uma deepfake, e, à esquerda, de uma fala real. A principal diferença da transformação CQT para outros tipos de espectrogramas é que ela é capaz de representar diferentes notas e escalas musicais.
Figura 3: Transformação CQT

Fonte: Constant-Q transform toolbox for music processing
Figura 4: Versão inicial dos espectrogramas reais e falsos


Fonte: Imagem dos autores
A próxima etapa consistiu no processamento do Dataset. Vale lembrar que atacantes cibernéticos introduzem pequenas alterações - ruídos - nos áudios, burlando tais sistemas, fazendo com que a robustez dos modelos de detecção existentes acabe sendo prejudicada.
Assim, foi desenvolvido um programa para adicionar sons ambientes nos áudios, e ruídos nos espectrogramas, sendo realizados esses dois procedimentos, bem como uma combinação dos dois processos. Com esta abordagem, é maximizada a diversidade de dados e minimizada a chance de ocorrer o enviesamento do modelo.
Dessa forma, foram feitas tais alterações, para cada áudio, escolhendo proporções de maneira arbitrária, como pode-se observar abaixo:
- 100% dos áudios foram convertidos para espectrogramas e não sofreram nenhum tipo de modificação;
- 16,7% dos áudios tiveram sons ambiente adicionados e então foram convertidos para espectrogramas;
- 16,7% dos áudios foram convertidos para espectrogramas e tiveram ruídos adicionados;
- 16,7% dos áudios tiveram sons ambiente adicionados e então foram convertidos para espectrogramas, que terão também ruídos adicionados.
A introdução de ruídos ocorreu através da extração de amostras de uma distribuição normal parametrizada no formato (tamanho) dos espectrogramas, com desvio padrão de 0,5 e valor esperado valendo 0. Essas amostras foram, então, sobrepostas aos espectrogramas, criando ruídos nos mesmos. A fórmula da distribuição normal pode ser observada na Figura 5, onde σ é o desvio padrão e μ é o valor esperado.
Figura 5: Distribuição normal

Fonte: Distribuição normal
Já os sons de ambiente citados foram pegos da base de dados “ESC: Dataset for environmental sound classification” (PICZAK, 2015), que contém sons de animais, paisagens naturais, e ambientes doméstico e urbano, sendo estes sobrepostos aos áudios originais utilizando a biblioteca pydub em Python.
Então, foi desenvolvido o foco do projeto: um modelo de inteligência artificial capaz de identificar áudios sintéticos. Após realizar pesquisas a respeito do tema, optou-se por utilizar visão computacional para esse fim, por ela considerar não só o conteúdo do áudio mas também a sua representação visual, aumentando a precisão da detecção. Assim, foi vital identificar arquiteturas de redes neurais aptas para a realização da tarefa.
Realizou-se uma revisão bibliográfica dos métodos utilizados até então, e selecionou-se alguns para testar e comparar seus desempenhos e capacidade de classificação, escolhendo os que melhor se encaixaram na resolução do problema e entregarem resultados satisfatórios. Três arquiteturas principais foram encontradas e possuem tal habilidade: a rede neural convolucional (CNN) (LECUN, 1989), a rede adversária generativa com classificador externo (EC-GAN) (HAQUE, 2021) e o Vision Transformer (DOSOVITSKIY, 2020).
Com respeito à CNN, esta é uma arquitetura de rede neural que utiliza camadas convolucionais e filtros a fim de perceber padrões em imagens e assim poder classificá-las (FUKUSHIMA, 1980). A arquitetura da CNN usada no projeto pode ser observada na Figura 6.
Figura 6 - Arquitetura da rede neural convolucional (CNN) desenvolvida

Fonte: Imagem dos autores
Cabe destacar que foram utilizadas técnicas de normalização e regularização na construção do modelo, com introdução de camadas de Batch Normalization e Dropout. A ideia principal do Dropout é eliminar aleatoriamente nós (juntamente com suas conexões) de uma rede neural durante o treinamento, evitando que eles se adaptem demais (SRIVASTAVA, 2013). Já o Batch Normalization permite usar taxas de aprendizado muito mais altas e ter menos cuidado com a inicialização. Ela também atua como um regularizador, em alguns casos eliminando a necessidade de Dropout (IOFFE, 2015).
Já em relação à EC-GAN, esta é uma adaptação da rede neural adversária generativa (GAN). Deixa-se claro, aqui, que as GANs não foram concebidas para classificar dados, mas sim a fim de gerar novos e parecidos com os originais. Por isso, Haque (2023) propôs a introdução de um classificador externo ao modelo, daí o nome External Classifier GAN. A estrutura e relação entre os diferentes modelos dessa abordagem pode ser observada na Figura 7.
Figura 7 - Arquitetura da rede adversária generativa com classificador externo (EC-GAN)

Fonte: Imagem dos autores
O Vision Transformer, por sua vez, é uma arquitetura de aprendizagem profunda que divide uma imagem de entrada em uma série de patches (em vez de dividir o texto em tokens, como em um Transformer tradicional), serializa cada patch em um vetor e o mapeia para uma dimensão menor com uma única multiplicação de matriz. Ele foi criado como uma alternativa à CNN, no contexto de classificação de imagens.
Tendo, então, as possíveis arquiteturas para a solução do problema, elas foram implementadas em Python utilizando a biblioteca TensorFlow e treinamentos iniciais foram realizados a fim de testar a entrega de resultados pelas mesmas. Assim, foi feita uma comparação com base numa análise qualitativa quantitativa da performance de cada arquitetura, levando em consideração parâmetros como precisão, taxa de erro e tempo de execução.
Entre as diferentes arquiteturas, a CNN foi a única cujo desempenho foi adequado, com tempo de execução e precisão eficientes para o conjunto de dados construído. Enquanto a GAN, por envolver três modelos distintos e um código complexo, levou um tempo de execução acima do esperado, o Vision Transformer consumiu memória excessiva, além da capacidade de processamento disponível. Além disso, o Vision Transformer necessitaria de quantidades massivas de dados, muito maiores do que o Dataset da pesquisa.
Então, foi feito um treinamento primário da CNN utilizando uma pequena amostra do conjunto de áudios, contendo espectrogramas de 5 vozes reais, rotuladas como real, em conjunto com suas deepfakes correspondentes, rotuladas como fake, além de espectrogramas de sons não humanos aleatórios, rotulados como other, totalizando cerca de 12.000 espectrogramas. Aqui, cabe destacar que, na versão inicial do modelo, ele possuía três saídas possíveis, incluindo sons aleatórios, o que foi retirado posteriormente por esse não ser o foco do projeto. O treinamento realizado é descrito a seguir:
- Ele foi realizado por 25 iterações, em um computador com processador 13th Gen Intel(R) Core(TM) i7-1355U 1.70 GHz, e memória de 16,0 GB.
- Os hiperparâmetros usados podem ser visualizados na Tabela 1 (são encontradas mais informações sobre eles no Anexo B).
Tabela 1 - Hiperparâmetros e seus respectivos valores utilizados no treinamento inicial da CNN desenvolvida
| Hiperparâmetro | Valor utilizado |
|---|---|
| Número de epochs | 100 |
| Tamanho do batch | 32 |
| Taxa de aprendizagem | 0.01 |
| Paciência | 15 iterações |
| Função de loss | Categorical Cross Entropy |
| Optimizador | Adam |
Fonte: Tabela dos autores
Os resultados podem ser visualizados na Figura 8, que possui dois gráficos: um superior e um inferior, que mostram, respectivamente, a precisão e o erro do modelo ao longo das iterações de treinamento.
Figura 8 - Treinamento inicial da CNN desenvolvida

Fonte: Imagem dos autores
Posteriormente à escolha da CNN, o treinamento do modelo foi ampliado, isto é, foi usado o Dataset inteiro, usando os mesmos hiperparâmetros e computador da Tabela 1, visando aumentar sua eficácia, sendo esta fase crucial para os resultados do projeto. No entanto, mesmo com grandes quantidades de dados, a rede neural ficou enviesada, com acurácias próximas a 99% ainda nos primeiros ciclos de treinamento. Os resultados do treinamento (acurácia e taxa de erro) podem ser observados na Figura 9.
Assim, foi feita uma investigação sobre as possíveis causas desse comportamento, onde foram testadas diferentes abordagens, como:
- Geração de espectrogramas de áudios provenientes de Datasets como o “VCTK” (VEAUX, 2017) e o “ASVspoof 2019” (YAMAGISHI et al., 2019), que possuem, respectivamente, gravações reais e falas sintéticas na língua inglesa, sendo esses dados adicionados ao nosso Dataset;
- Remoção dos dados com ruído, alimentando a rede neural somente com imagens de áudios brutos;
- Uso de espectrogramas coloridos, em vez de na escala cinza.
Figura 9 - Treinamento CNN: Versão completa do Dataset inicial

Fonte: Imagem dos autores
Em todos os testes realizados, o modelo continuou com precisão acima do esperado. Isso levou à revisão da sua arquitetura, da forma como os espectrogramas estavam sendo gerados, e mesmo da metodologia empregada na detecção de deepfakes. É válido notar que o modelo teve um pior desempenho para os áudios com ruído em relação aos sem, confirmando que eles prejudicam a identificação.
Para verificar se o problema residia na arquitetura convolucional, foi decidido treinar o modelo sob as mesmas condições do treinamento primário citado anteriormente, porém utilizando o Dataset “Urban Sound” (SALAMON, 2014), que contém espectrogramas de 27 horas de áudio pertencentes a 10 classes distintas. As imagens do mesmo são coloridas e com dimensões superiores às do Dataset da pesquisa usado até então.
O desempenho do modelo não foi satisfatório nos primeiros epochs, com precisão abaixo de 1%, o que indicou que o overfitting ocorrido anteriormente durante o treinamento estava relacionado aos dados, e não ao modelo.
Desse modo, foram gerados espectrogramas semelhantes aos do “Urban Sound” - coloridos e com dimensões maiores no eixo do tempo - mais especificamente, 512px por 256px - para todas as vozes e deepfakes do nosso Dataset. Foi então realizado um treinamento visando observar o comportamento do modelo. Os hiperparâmetros usados podem ser visualizados na Tabela 2.
Tabela 2 - Hiperparâmetros e seus respectivos valores utilizados no treinamento da CNN com o Dataset oficial
| Hiperparâmetro | Valor utilizado |
|---|---|
| Número de epochs | 100 |
| Tamanho do batch | 128 |
| Taxa de aprendizagem | 0.01 |
| Paciência | 15 |
| Função de loss | Categorical Cross Entropy |
| Optimizador | Adam |
Fonte: Tabela dos autores
Sob essas condições, ele teve mais dificuldade em distinguir as deepfakes das vozes reais, com uma precisão no primeiro ciclo de treinamento de 95%, ao invés de 99% como anteriormente, o que indicou que informações estavam sendo perdidas nas antigas imagens na escala cinza e com o comprimento reduzido. O resultado desse treinamento pode ser observado na Figura 10.
Como o produto desses testes foi satisfatório, decidimos tomar essa última abordagem como definitiva.
Figura 10 - Treinamento da CNN usando Dataset oficial sem ruídos

Fonte: Imagem dos autores
Paralelamente ao processo de treinamento do modelo, uma aplicação web foi desenvolvida. Seu objetivo é permitir aos usuários, de qualquer idade, instrução ou localidade, selecionarem arquivos de áudio que desejam classificar. Com isso, os áudios são enviados a uma API também desenvolvida.
Para chegar a esse resultado, foi iniciado um projeto com o framework Next.js que permite um desenvolvimento fluido de páginas web. Ademais, foram utilizados recursos essenciais como: a linguagem de programação Typescript, para proporcionar tipagem ao código e assim evitar que erros aconteçam; e o Tailwind CSS, para a estilização através de classes dos componentes das páginas.
Além disso, foram adicionadas bibliotecas, a citar: Shadcn UI, para a adição de componentes visuais padronizados e elegantes; Content Layer, para a adição de conteúdo Markdown; Next Themes, para permite a troca entre os temas claro e escuro; e Axios, para a comunicação com o backend; entre outros.
Posteriormente, foram desenvolvidos os componentes Header e Footer, para permitir que o usuário possa navegar pelas páginas, bem como para melhorar a divulgação do nome do site. Além disso, uma tabela informativa foi adicionada na página principal para comunicar algumas conquistas do projeto, como o tamanho do Dataset, a acurácia do modelo, as arquiteturas testadas, etc.
Após isso, foi criada a página de classificação, onde o usuário seleciona os arquivos de áudio de seu dispositivo, a partir de uma área de input. Ao clicar no botão “classificar”, estes são enviados para a API. É importante notar que validações foram adicionadas, para garantir que, em primeiro lugar, formatos que não sejam próprios de arquivos áudio (wav, mp3, ogg, m4a) não sejam permitidos, e, segundamente, que mais de 3 arquivos não sejam selecionados, visto que esse foi o limite definido para a classificação. Para fazer a comunicação com a API, utiliza-se a biblioteca Axios, que entrega informações úteis durante o upload dos arquivos, como o progresso do mesmo, a ocorrência ou não de erros, entre outras.
Em seguida, foi adicionada a página de sobre o projeto. Nela, arquivos escritos em Markdown são compilados para elementos da web, gerando páginas em estilo de documentação. Foram adicionadas, então, informações sobre o desenvolvimento da pesquisa, os objetivos propostos e alcançados, os resultados objetivos, etc. Para isso, foi utilizada a biblioteca Content Layer, que faz a conversão dos arquivos md e mdx para código JavaScript, que pode, então, ser renderizado na página.
Na sequência, foi hora de adicionar, na página principal, mais elementos que pudessem dar ao usuário uma sensação de confiabilidade e credibilidade do projeto. Para esse fim, foram adicionados Cards, com áudios que serão classificados com o modelo final, juntamente com a acurácia e a previsão da classificação. Além disso, o usuário pode ouvir esses áudios para comparar com a veracidade dos mesmos. Não apenas isso, mas um globo terrestre foi incluído para passar a ideia de que a pesquisa visa ter alcance global, permitindo ajudar a qualquer um, em qualquer lugar.
Para concluir as páginas a serem adicionadas, foi criada a página de autores. Nela, foram adicionadas as informações, como foto, nome, descrição e contatos de cada um dos participantes do projeto, bem como dos orientadores do mesmo.
Já com relação à API, esta foi desenvolvida em Python utilizando o framework Flask, que nos permitiu criar esse elo. Para fazer a classificação, foi criado um controller - que é a parte do backend que recebe a requisição - para validar os parâmetros passados (garantir que há de fato um arquivo passado) e extrair o áudio dos mesmos. Este arquivo é então passado para uma lógica onde do áudio é extraído o espectrograma com o uso da biblioteca Librosa. Os bytes do espectrograma são, em memória, encaminhados para o módulo onde a classificação ocorrerá, de fato. No inference_handler, o modelo classificatório é carregado e o áudio é então classificado. Os resultados desse processo (a acurácia e a previsão) são então retornados para o frontend - parte visual do software e que é o objeto de interação com o usuário, neste caso, o website. A arquitetura da API pode ser observada na Figura 11.
Partiu-se, então, para a hospedagem da API no Render, que é uma plataforma para hospedagem gratuita de serviços. Entretanto, após ter sido configurada e hospedada, notou-se o seguinte problema: após 15 minutos sem receber requisições, o servidor no qual a API está hospedada entra em inatividade. Quando isso acontece, aquele demora em média de 1 minuto para voltar à atividade, o que implica em um grande aumento do tempo de resposta, o que pode piorar a experiência do usuário; ao voltar à atividade, as respostas chegam rapidamente.
Para contornar o empecilho, decidiu-se criar um script Keep Alive, que é um programa escrito em Python e que, a cada 14 minutos, faz uma requisição para a API enviando um áudio de exemplo. Assim, é garantido que, enquanto o programa estiver rodando, o servidor não entrará em inatividade. Com isso, bastou compilar o mesmo e adicioná-lo a uma tarefa automática no computador, para que, quando este ligar, o script já comece a rodar em segundo plano no dispositivo.
Figura 11 - Estrutura da API utilizada para conexão com o website

Fonte: Imagem dos autores
Fica claro, portanto, que se trata de uma API simples, quando comparada com as utilizadas em projetos mais complexos, visto que tem apenas uma rota, de onde chega o áudio enviado pelo usuário e de onde sairá a resposta da classificação para o mesmo. Entretanto, é desta simplicidade que o projeto precisa, já que seu foco é no desenvolvimento de uma inteligência artificial eficaz e robusta que possa entregar resultados satisfatórios ao usuário final.
Cabe destacar que o modelo presente na API não é o mais recente desenvolvido, mas sim a versão inicial treinada com espectrogramas em preto e branco de dimensões 256px por 256px. Isso pois a plataforma de hospedagem utilizada possui um limite gratuito de 500 MB de memória, e o modelo atual necessita de um valor maior. No entanto, a versão anterior também possui uma eficácia elevada, o que acreditamos que não impactará significativamente no produto final.
Por fim, a documentação da API pode ser consumida no seguinte link: https://github.com/Unfake-Official/server, enquanto a documentação do website está presente nessa página: https://github.com/Unfake-Official/web.